機械学習で女の子の声になろう
これはKCS AdventCalendar2021 25日目の記事です。
← 24日目
おはようございます。KCS 所属理工学部情報工学科2年の Tlapesium です。
まえがき
美少女になるということはこの世の誰もが夢見ることでしょう[要出典]。近年では、VRの登場によって、誰でも気軽に美少女になることができ、美少女の門戸は大きく開かれたと言っても過言ではないでしょう。しかしながら、VRでも解決できていない大きな問題があります。それは声です。声だけは簡単に変えることが難しいのです。その結果、美少女のアバターからおじさんの声が聞こえるということが一般的になっています。(こちらの方が良いという訓練された方もいるようですが…) しかし、個人的には、美少女からは美少女の声が聞こえてきてほしいものです。
ところで、どういうわけか私はKCSのAI班に所属していることになっているらしいので、それを機械学習の力で解決することにします。
MaskCycleGAN-VC
今回この記事で紹介するMaskCycleGAN-VCはCycleGANを応用した声質変換の手法です。CycleGANでは二つのドメイン間の画像を変換しますが、MaskCycleGAN-VCでは二人の話者の声質を相互に変換することができます。
MaskCycleGAN-VCは6つのネットワークによって構成されており、役割の詳細は以下の通りです。
- Generator-XY : 話者Xの声を話者Yの声に変換する。
- Generator-YX : 話者Yの声を話者Xの声に変換する。
- Discriminator-X : Generator-YXによって変換された話者Xの声と本物の声を判別する。
- Discriminator-Y : Generator-XYによって変換された話者Yの声と本物の声を判別する。
- Discriminator-X2 : Generator-XYとGenerator-YXを通して元に戻した話者Xの声と本物の声を判別する。
- Discriminator-Y2 : Generator-YXとGenerator-XYを通して元に戻した話者Yの声と本物の声を判別する。
MaskCycleGAN-VCももちろんGANなので、6つのネットワークをすべて使うのは学習時だけで、推論時にはGenerator-XYかGenerator-YXのどちらかのみを用いることになります。
これらのネットワークの構造や損失関数について詳しく解説していきたいと思います。
損失関数
敵対性損失
$$ \mathcal{L}^{X \to Y}_{adv} = \mathbb{E}_{\boldsymbol{y} \sim P_Y} [\log D_Y (\boldsymbol{y})] + \mathbb{E}_{\boldsymbol{x} \sim P_X} [\log ( 1 – D_Y (G_{X \to Y} (\boldsymbol{x} ) ) )]$$
いわゆる GAN の損失です。Binary Cross Entropy をベースに、本物を正しく本物と、偽物を正しく偽物と識別できればできるほど値が大きくなるような損失関数となっています。Generatorはこれを最小化するように学習します。
サイクル一貫性損失
$$ \mathcal{L}^{X \to Y \to X}_{cyc} = \mathbb{E}_{\boldsymbol{x} \sim P_X} [ {\| G_{Y \to X} (G_{X \to Y} (\boldsymbol{x})) – \boldsymbol{x} \|}_1 ] $$
いわゆる CycleGAN の損失です。再構成した $\boldsymbol{x}$ ともとの $\boldsymbol{x}$ の差分の L1 ノルムです。
恒等写像損失
$$ \mathcal{L}^{X \to Y}_{id} = \mathbb{E}_{\boldsymbol{y} \sim P_Y} [ {\| G_{X \to Y} ( \boldsymbol{y} ) – \boldsymbol{y} \|}_1 ] $$
例えば、Generator-YX に話者 X の声を入力した際にそのまま出力すると最小化される損失です。話者ごとの声の共通点を維持する効果があるようです。[要出典]
第二敵対性損失
$$ \mathcal{L}^{X \to Y \to X}_{adv2} = \mathbb{E}_{\boldsymbol{x} \sim P_X} [\log D’_X (\boldsymbol{x})] + \mathbb{E}_{\boldsymbol{x} \sim P_X} [\log ( 1 – D’_X (G_{Y \to X} (G_{X \to Y}(\boldsymbol{x}) ) ) )]$$
MaskCycleGAN-VC では再構成した $\boldsymbol{x}$ についても敵対性損失を適用します。なんかいい感じになるっぽいです。注意点として、Discriminatorは敵対性損失の時とは違うものを一つずつ用意します。
Discrimiantorを訓練する際には敵対性損失のみを使い、Generatorを訓練する際には四種類すべてを使います。Generatorを訓練する際に使用する損失関数は以下の通りです。
$$ \mathcal{L}_{full} = \mathcal{L}^{X \to Y}_{adv} + \mathcal{L}^{Y \to X}_{adv} + {\lambda}_{cyc}( \mathcal{L}^{X \to Y \ to X}_{cyc} + \mathcal{L}^{Y \to X \to Y}_{cyc}) \\ + {\lambda}_{id} (\mathcal{L}^{X \to Y}_{id} + \mathcal{L}^{Y \to X}_{id}) + \mathcal{L}^{X \to Y \ to X}_{adv2} + \mathcal{L}^{Y \to X \to Y}_{adv2} $$
${\lambda}_{cyc}$ と ${\lambda}_{id}$ は損失関数を調整するための係数で、論文ではそれぞれ $10$ と $5$ を採用しています。
ネットワーク構造
CycleGAN-VC2 と同様のネットワークを利用しています。
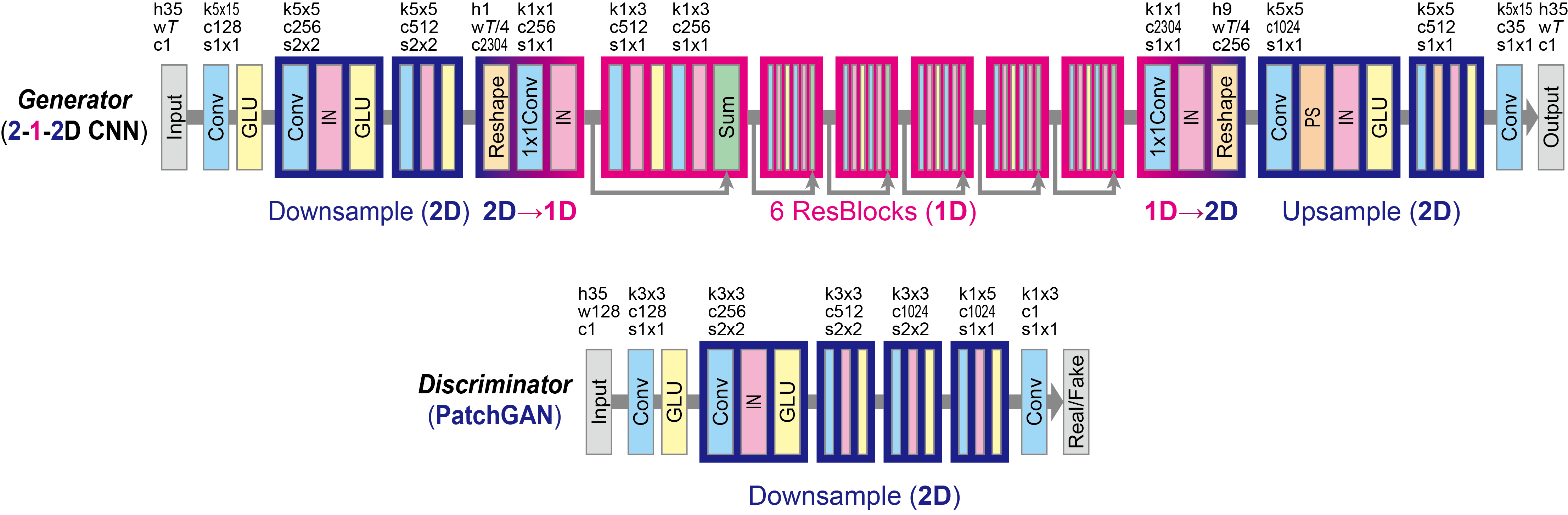
CycleGAN-VC2 との相違点として、入力に適用したマスクの情報を追加するため、入力のチャンネル数が 2 となっています。また、CycleGAN-VC2 ではメルケプストグラムを入力としていましたが、MaskCycleGAN-VC ではメルスペクトログラムを入力とするため、高さが 35 から 80 になっています。
Vocoder
これは厳密にはMaskCycleGAN-VCの一部ではありませんが、必須なのでここに書いておきます。
MaskCycleGAN-VCはメルスペクトログラムを入出力とします。波形をメルスペクトログラムに変換するには短時間フーリエ変換を行えばいいのですが、一方、メルスペクトログラムをフーリエ逆変換にかけても、位相などの情報が欠けてしまっているため高品質な音声を得ることはできません。そこでVocoderを用いることで、メルスペクトログラムから高品質な音声を復元することができます。今回はParallelWaveGANのJNASデータセットで訓練済みのモデルを使用しました。(Vocoderも一緒に学習させることでより品質の高い音声を復元できるかもしれませんが、Vocoderの学習にはMaskCycleGAN-VCの比にならない計算量が必要なので今回はしていません。ゆるして。)
学習
Generator を学習させる際に、最初に入力させる画像にマスクを用いて意図的に欠損を作り、欠損を復元しつつ変換するようにモデルを学習させます。このようにすることでモデルに時系列の情報を学習させることができ、精度が向上すると論文に書いてありました。すごい。
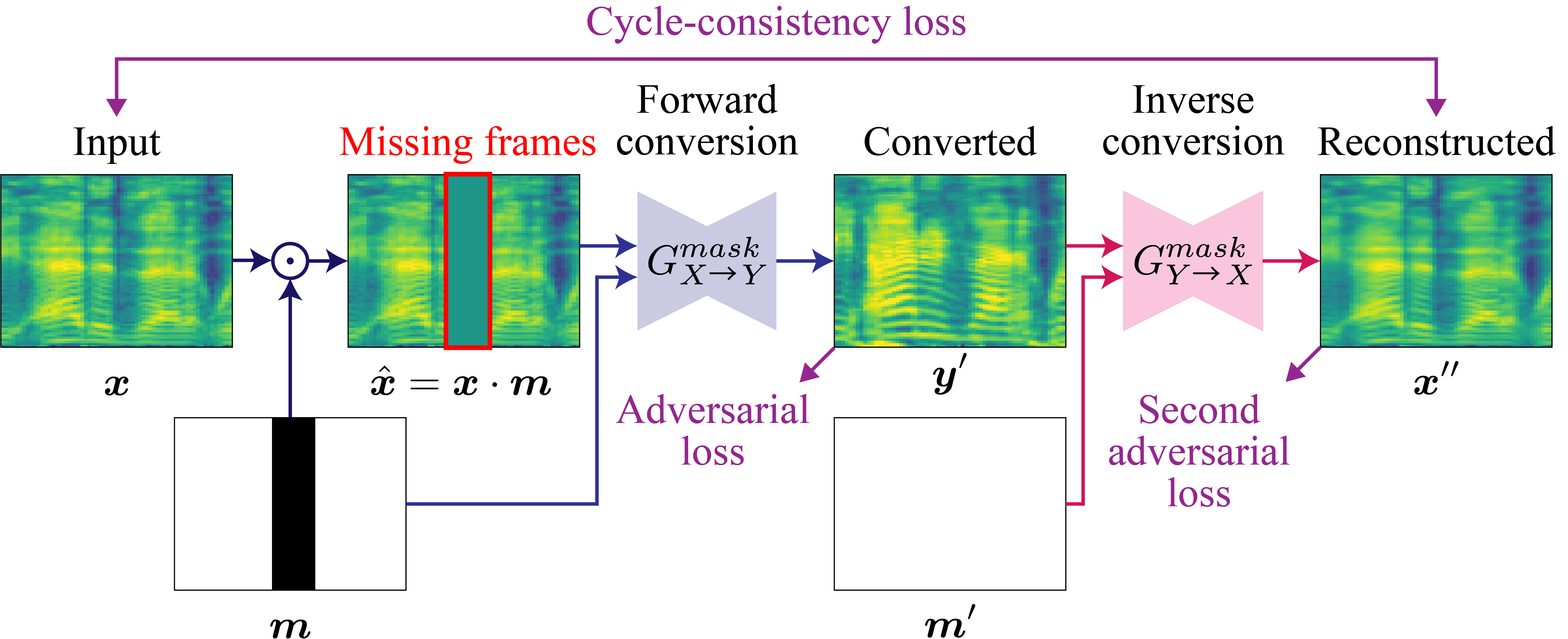
上記の画像からわかる通り、マスクを適用するのは最初の画像に対してのみです。また、Discriminatorの学習ではマスクは用いません。
マスクの大きさについては参考文献 1 の論文で議論されており、0 % から 50 % のランダムな大きさの連続したマスクで学習させるのが一番精度が高かったようです。
結果
今回、MaskCycleGAN-VCの再現実装を行い、筆者の声をつくよみちゃんコーパス (参考文献 4) の声に変換をするように学習を行ったので、その結果を掲載したいと思います。
「はわわ」のあたりとかちょっと失敗してますね。あと全体的にちょっとノイズがある感じがします。それ以外はだいたい良さげです。
再現実装のコードはあまりにも汚いため公開しません、ごめんね。
参考文献
- MaskCycleGAN-VC
- kan-bayashi / ParallelWaveGAN: Parallel WaveGAN implementation with Pytorch
- CycleGAN-VC2
- つくよみちゃんコーパス